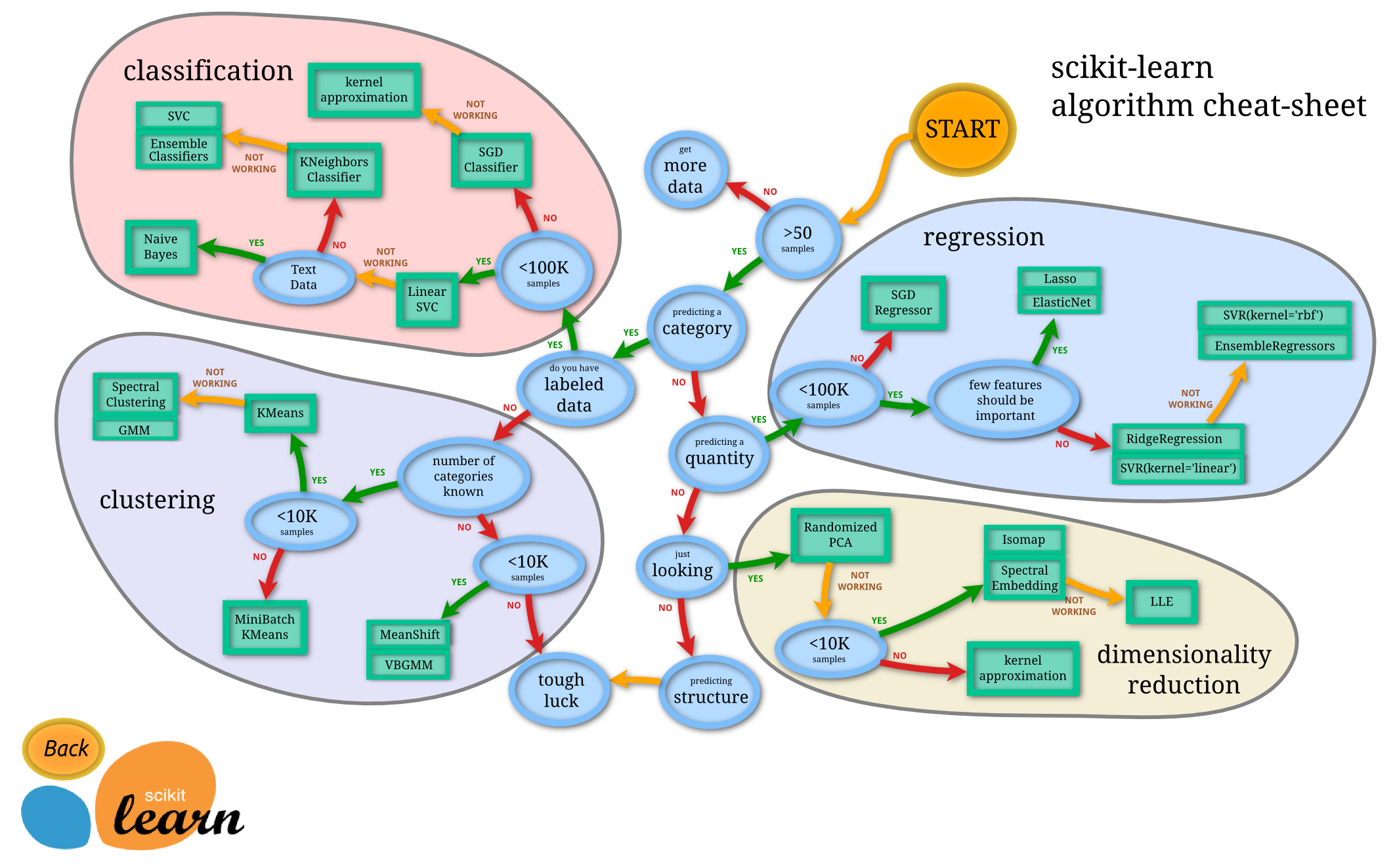
Les différents algorithmes d'apprentissage automatique
Définition de l’apprentissage automatique
L'apprentissage automatique (ML) est un domaine de l'intelligence artificielle qui développe des algorithmes capables d'apprendre à partir des données pour exécuter des tâches sans instructions explicites.
Des exemples incluent la reconnaissance faciale, la prédiction des prix, ou le tri des e-mails.
Catégories principales
-
Apprentissage supervisé Les algorithmes apprennent à partir de données avec des étiquettes (labels) connues (ex. : prix d'une maison ou catégorisation d'e-mails).
- Régression : Prédire une variable continue (ex. : prix).
- Classification : Attribuer une catégorie (ex. : spam ou non-spam).
Exemple : Prédire le prix d'une maison en fonction de la surface, l’emplacement, et l’année de construction.

-
Apprentissage non supervisé Les algorithmes analysent des données sans connaître de vérité préalable.
- Clustering : Regrouper des données similaires (ex. : trier automatiquement des e-mails en groupes).
- Réduction de dimensions : Simplifier les données sans perdre trop d’information (ex. : compresser une image tout en reconnaissant ses objets).
Principaux algorithmes
-
Régression linéaire
Trouve une relation linéaire entre une entrée et une sortie pour minimiser l'erreur de prédiction.Exemple : Relation entre taille et pointure : chaque pointure de plus = 2 cm de plus en taille (exemple simplifié).
-
Régression logistique
Prédit des probabilités pour des classes (ex. : homme ou femme selon taille/poids).
Utilise une fonction sigmoïde pour modéliser les classes. -
K-Nearest Neighbors (KNN)
Prend la moyenne des K plus proches voisins pour prédire une valeur (classification ou régression).AttentionProblème d’overfitting si K est trop petit ou underfitting si trop grand (tester plusieurs K pour savoir).

-
SVM (Support Vector Machines)
Trace une limite qui sépare des classes avec une marge maximale pour éviter les erreurs.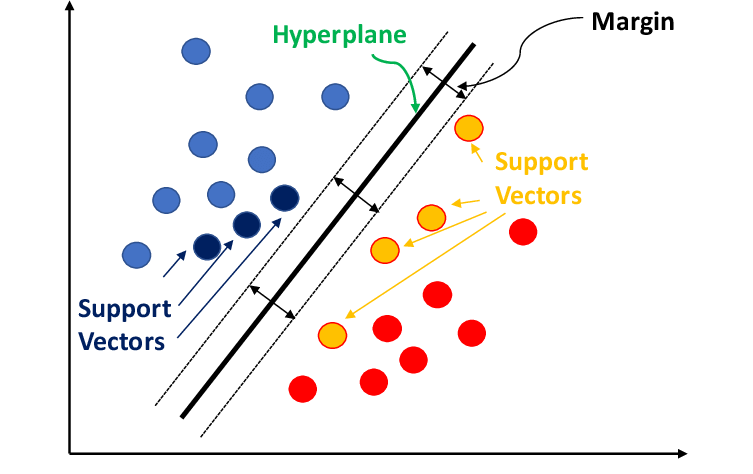
-
Arbres de décision Modèle des décisions successives sous forme d’arbre, basé sur des règles “oui/non”.
-
Forêts aléatoires (Random Forests) Combine plusieurs arbres pour éviter le surapprentissage. Chaque arbre vote pour une prédiction finale.
-
Boosting (ex. : AdaBoost, Gradient Boosting) Corrige les erreurs de modèles précédents pour améliorer la précision.
-
Réseaux de neurones (Deep Learning)
- Utilisent des layers cachées pour détecter automatiquement des relations complexes.
- Exemple simplifié : Reconnaître un chiffre malgré des écritures différentes.

Apprentissage non supervisé : Clustering
- K-Means Clustering : Regroupe des données selon leur proximité avec des centres de clusters.
- Autres techniques : Clustering hiérarchique, DBScan.
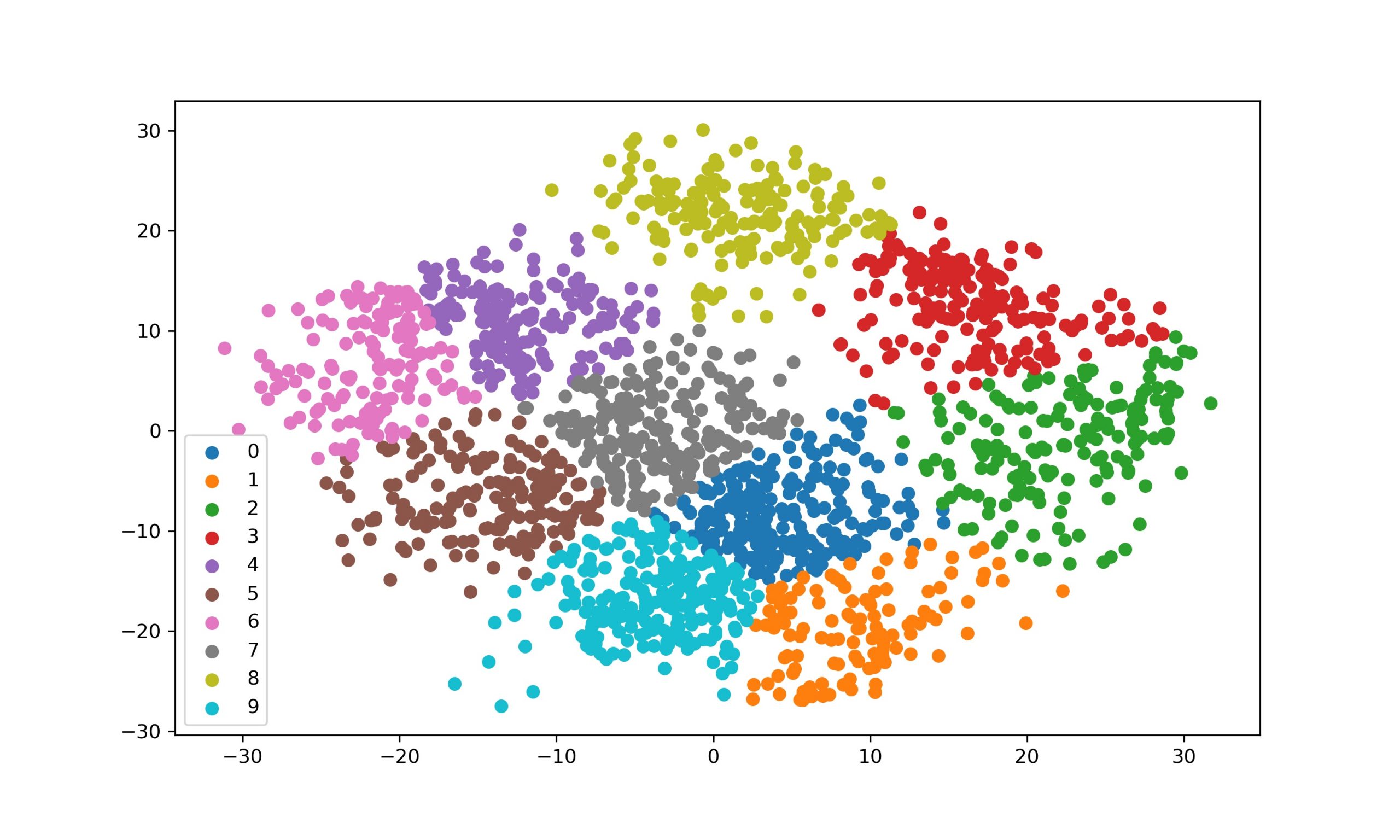
Réduction de dimensions
- Exemple : La réduction via PCA (Analyse en Composantes Principales) fusionne des variables corrélées pour simplifier les données.
Résumé des algorithmes
| Algorithme | Type | Exemple d’utilisation |
|---|---|---|
| Régression linéaire | Régression | Prédire le prix d’une maison. |
| KNN | Les deux | Catégoriser des individus. |
| Forêts aléatoires | Les deux | Détection de fraude. |
| Réseaux de neurones | Les deux | Reconnaissance d’image. |
| K-Means Clustering | Non-supervisé | Groupement d’e-mails similaires. |